
Search engines find information through crawling (which means they request / fetch a URL) to then analyze what they find on the URL.
robots.txt rules should only be used to control the search engine crawling process but not indexing process. This means, most Search Console blocked by robots.txt errors arise due to incorrect rules used by the website owner as opposed to incorrect website setup.
What to Do When robots.txt File is Auto Generated?
Certain Content Management Systems such as Blogger, Google Sites, WordPress Hosted Sites, WiX or Other Platforms may auto generate robots.txt file. In such cases, you can not update the actual robots.txt file if it is auto generated. In such scenarios, the only thing you can do to remedy Page indexing issues is make certain that XML sitemap you’ve submitted to Google search console contains only the URLs you want Google to crawl and index.
Video Lesson for Fixing Blocked by robots.txt Errors
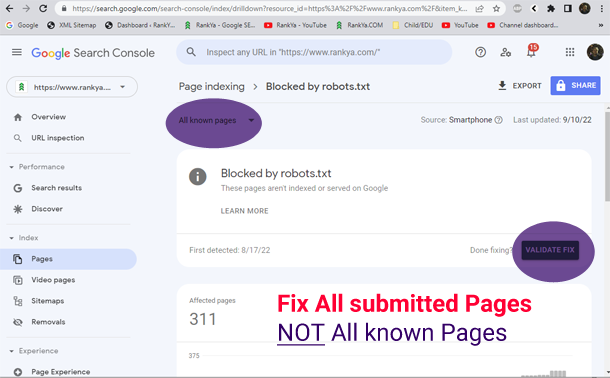
How to Fix URL blocked by robots.txt – Page Indexing Reports
When submitted pages have blocked by robots.txt file issues. You can test and verify which rules in robots.txt file disallow Google crawlers using robots.txt tester tool in Search Console.

Once you confirm which rules are blocking Google’s access, then, it is just matter of deleting that line (or lines) of rules in the actual robots.txt file on the web server.
About /robots.txt
The first file search engines like Google or Bing or other law abiding web crawlers look for is the robots.txt file. Webmasters use robots.txt file to provide instructions to user-agents (web crawlers, bots) as to what (if any) part of a website they are allowed to crawl and access. This is done using Robots Exclusion Protocol directives placed in robots.txt file.
This ensures website owners who do not want search engines to access their website can tell ALL (*) bots to NOT crawl their website by simply placing this in the robots.txt file.
User-agent: *
Disallow: /
Since most website owners want to allow Google to crawl their website, using the above disallowing rule is not ideal and should NOT be used unless you are developing a website that is not ready to go live.
But what if there is part of a website that you do NOT want Googlebot to crawl? Then you would do something like this:
User-agent: *
Disallow: /privatepage
The Reason Website Owners Get robots.txt Rules Messed Up
The most common reason Google Search Console Page indexing reports Blocked by robots.txt issues arise is because a website owner thinks that by using robots.txt they can make control which URLs are visible / indexable to search engines.
When you want web pages not indexed by Google, remove the robots.txt file and use a noindex directive.


Great tutorial about robots.txt file. Blocked by robots txt file issues are easily solved.
Thanks for your great tutorial.
I use wordpress for most of the time and SEO plugin like rank math handles the issue quite well! nonetheless I still want to check if the robots.txt file has xml sitemap link in it. I wouldn’t bother making changes to my robots txt file unless I am confident enough to block any particular directory. Because you may end up blocking any directory that could be harmful like blocking a JS. And you never know unless you are love checking GSC for technical error.
thanks for awesome info, Like your effort!
Most website owners use robots.txt file thinking the rules within robots.txt will block Google from indexing. But the truth is, robots.txt file directives control access for crawling process, but not indexing process. Meaning, often times, robots.txt file may include URL patterns in hope to control Google access, but if Google can see the URL (perhaps following another link on the website, or directly requesting the URL from an external website) then Google may still index the URL. Hence, don’t even bother using robots.txt file when unsure what it actually does. Learn more here: https://developers.google.com/search/docs/crawling-indexing/robots/intro
Which robots.txt should I use for my blogger blog?
Remove what you currently have in your website robots.txt file. Instead just use
User-agent: *
Disallow:
And LEAVE IN PLACE the XML Sitemap links
Because I think Disallow: /20* maybe causing indexation issues with Google.
thank you
You’re welcome, I am glad this has assisted remedying your website Google Search Console blocked by robots.txt issue 🙂